
11. Datenspeicherung¶
Es gibt eine Reihe von Möglichkeiten wie man Daten speichern kann. Welche Methode am besten ist, hängt von Kriterien ab wie:
- Datentyp
- Datenmenge
- Zugriffsgeschwindigkeit
- Erweiterbarkeit
- Implementierungsaufwand vs. Nutzen
11.1. Tabellenformate¶
11.1.1. CSV / Text Format¶
Ein sehr verbreitetes Import- und Exportformat für Datenbanken und Tabellenkalkulationen ist das CSV-Format (Comma Separated Values).
CSV-Dateien sind Textdateien, die zeilenweise Datensätze enthalten welche
mit Trennzeichen (,, ;, …) versehen sind z.B.:
Marke;Modell;Leistung
Porsche;911;350
Skoda;Octavia;140
Audi;Q3;110
Dabei ist die erste Zeile die Datenbezeichnung. Solche Daten können mit unterschiedlichsten Softwareapplikationen erzeugt werden.
Die einfachste Möglichkeit aus Python Daten zu schreiben,
ist unter „Daten in eine Datei schreiben“ erläutert d.h. mittels
for und print Statement.
Eine solche Datei kann mit dem Python csv Modul eingelesen werden:
In [1]: import csv
In [2]: with open("daten.csv", "r") as csvfile:
...: reader = csv.reader(csvfile, delimiter=";")
...: for row in reader:
...: print(row)
...:
['Marke', 'Modell', 'Leistung']
['Porsche', '911', '350 ']
['Skoda', 'Octavia', '140 ']
['Audi', 'Q3', '110 ']
bzw. wieder in eine Datei geschrieben werden:
In [3]: with open("test_daten.csv", "w", newline='') as csvfile:
...: writer = csv.writer(csvfile, delimiter=';')
...: writer.writerow(['Marke', 'Modell', 'Leistung'])
...: daten = ( ['Porsche', '911', '350 '],
...: ['Skoda', 'Octavia', '140 '],
...: ['Audi', 'Q3', '110 '])
...: writer.writerows(daten)
Anmerkungen:
- Mit
"wb"statt"w"kann man Binärfiles schreiben (mit"rb"wieder lesen). - für korrekte Zeilenendungen auf unterschiedlichen Plattformen wird
newline=''empfohlen. (siehe https://docs.python.org/3/library/csv.html#id3) - Es können Files geschrieben werden, welche direkt von Microsoft EXCEL gelesen werden können (einfach anklicken im Explorer).
11.1.2. XLSX Format¶
Weit verbreitet ist das Microsoft XLSX File Format. Mit dem Modul openpyxl lassen sich diese Files direkt schreiben (siehe Beispiel daten_xlsx.py).
from openpyxl import Workbook # import der Bibliothek
wb = Workbook()
# Erzeugen eines Registerblattes
ws = wb.create_sheet("Meine Autos")
# Daten koennen direkt eingefügt werden
ws['A1'] = "Marke"; ws['B1'] = "Modell"; ws['C1'] = "Leistung"
# Zeilen anhaengen
ws.append(["Porsche", "911", 350])
ws.append(["Skoda", "Octavia", 140])
ws.append(["Audi", "Q3", 110])
# Speichern des Files
wb.save("daten.xlsx")
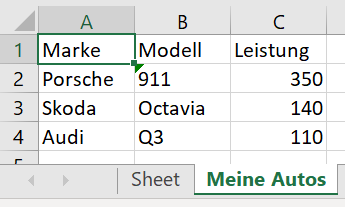
Das Lesen von XLSX ist wesentlich aufwendiger aufgrund von „Merged Cells“, Formeln, etc. und wird hier nicht näher behandelt. Ein einfaches Beispiel dazu (siehe daten_xlsx2.py):
from openpyxl import load_workbook
wb = load_workbook(filename = "daten.xlsx")
sheet_ranges = wb['Meine Autos']
print(sheet_ranges['A1'].value)
11.1.3. Python Pandas¶
Hat man große numerische Datenmengen welche manipuliert und analysiert werden, ist Python Pandas die richtige Bibliothek. Vereinfacht gesprochen steht dahinter ein sehr effizientes Tabellenformat mit vielen Analyse- und Visualisierungfunktionen.

Beispielsweise können sehr einfach xlsx Daten gelesen und verarbeitet werden (Fortsetzung des oberen Beispiels):
In [1]: import pandas as pd
In [2]: meineAutos = pd.read_excel('daten.xlsx', sheet_name='Meine Autos')
In [3]: print(meineAutos)
Marke Modell Leistung
0 Porsche 911 350
1 Skoda Octavia 140
2 Audi Q3 110
In [4]: print(meineAutos.values)
[['Porsche' '911' 350]
['Skoda' 'Octavia' 140]
['Audi' 'Q3' 110]]
11.2. XML Dateien¶
Das CSV Format ist
- einfach lesbar, aber
- nicht einfach erweiterbar und wartbar.
Alternative: Das XML Format (Extensible Markup Language). Dieses Format ist :
- eine hierarchisch aufgebaute Datenstruktur (erweiterbar), welche
- in einem lesbaren Textformat verfasst ist.
Für das obige Beispiel würde ein XML File so aussehen (daten.xml):
<?xml version="1.0" encoding="UTF-8"?>
<autohaus>
<auto>
<marke>Porsche</marke>
<modell>911</modell>
<leistung>350</leistung>
</auto>
<auto>
<marke>Skoda</marke>
<modell>Octavia</modell>
<leistung>140</leistung>
</auto>
<auto>
<marke>Audi</marke>
<modell>Q3</modell>
<leistung>110</leistung>
</auto>
</autohaus>
Man bezeichnet diese Datenstruktur als Document Object Model (DOM). Die Abbildung XML DOM Baum zeigt die grafische Darstellung.
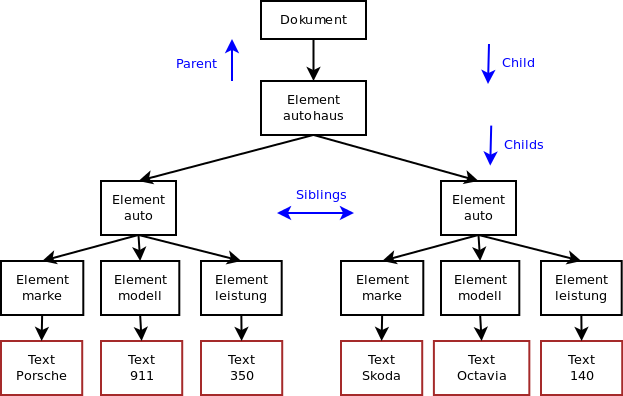
Beispiel eines XML DOM Baumes
Erklärung:
- Der Baum besteht aus Elementen.
- Übergeordnete heißen Parents, untergeordnete Childs und jene auf der gleichen Ebene Siblings.
- Auf der untersten Ebene werden die Daten als Text gespeichert.
Das Lesen/Schreiben kann mit folgenden Python Modulen implementiert werden:
xml.dom.minidomDocument Object Model, kurz DOM (liest alles in Speicher)xml.saxSimple API for XML, kurz SAX (liest fortlaufend in Speicher)xml.etree.ElementTree, einfacher als die beiden anderen, i.A. ausreichend.
Hier ein Beispiel (daten_xml_elementtree.py) mit xml.etree.ElementTree:
# Lade Modul
import xml.etree.ElementTree as ET
# Erzeuge Baum
baum = ET.parse('daten.xml')
# Lese Daten "liste"
liste = baum.getroot()
# Lese von "liste" alle
for auto in liste:
print(auto.find('marke').text, \
auto.find('modell').text, \
auto.find('leistung').text)
# Ausgabe
baum.write("test_daten.xml")
Ausgabe:
Porsche 911 350
Skoda Octavia 140
Audi Q3 110
Für Genaueres zu diesem Thema wird auf die Literatur verwiesen.
11.3. Datenbanken¶
Große bzw. komplexe Datenmengen benötigen entsprechende Verwaltungsprogramme. Obige Konzepte sind dafür nur bedingt geeignet. Man verwendet daher Datenbanken.
Bei einer Datenbank wird zwischen dem Programm und dem Massenspeicher (Festplatte, ..) ein Zwischenlayer (Datenbanksystem) eingeführt (siehe Abbildung Datenbankschnittstelle).
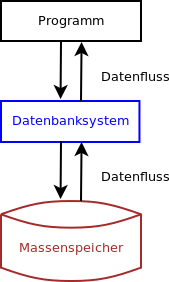
Datenbankschnittstelle
Allgemeines:
- Das Datenbanksystem nimmt dabei Abfragen, sogenannte Queries (Anfragen) entgegen und gibt Datensätze zurück.
- Für Abfragen von relationalen Datenbanken wurde die Sprache SQL (Structured Query Language) entwickelt.
- Python stellt die Module
mySQLdbundsqlite3zur Verfügung um via SQL mit einer Datenbank zu kommunizieren.